KI-Sichtbarkeit von Marken 2026: Original-Research-Studie
KI-Sichtbarkeit von Marken 2026 – Original-Research mit Datenvisualisierung
# KI-Sichtbarkeit von Marken 2026: Original-Research-Studie
Wie wurde diese Studie durchgeführt?
Diese Studie analysierte, wie häufig und unter welchen Bedingungen Marken in KI-generierten Antworten auf den drei dominierenden KI-Suchplattformen erscheinen. Die Untersuchung wurde von Alexandrya.AI in Q1 2026 mit einer systematischen abfragebasierten Methodik auf ChatGPT (GPT-4o), Google Gemini 1.5 Pro und Perplexity Pro durchgeführt. Alle Abfragen liefen unter kontrollierten Bedingungen — ausgeloggt, privates Browsing, standardisierter geografischer Standort — um Personalisierungseffekte zu minimieren.
Welchen Umfang hatte die Studie?
Die Studie umfasste 500 Marken aus 12 B2B- und B2C-Branchenkategorien, darunter SaaS, Professional Services, Finanzdienstleistungen, Healthcare, Fertigung und Consumer Electronics. Jede Marke wurde gegen mindestens 20 standardisierte Abfragen pro Kategorie geprüft — das ergibt mehr als 10.000 einzelne KI-Antwort-Beobachtungen. Die Marken repräsentieren ein Spektrum von Enterprise (500+ Mitarbeiter) bis Mid-Market (50–500 Mitarbeiter), um die Generalisierbarkeit der Ergebnisse sicherzustellen.
Welche KI-Modelle wurden einbezogen?
Drei Plattformen wurden einbezogen: ChatGPT (GPT-4o mit Browse, ausgeloggt), Google Gemini 1.5 Pro (AI Overviews, US-Englisch) und Perplexity Pro (Standard-Modell, Websuche aktiviert). Diese drei repräsentieren die KI-Suchplattformen mit dem höchsten dokumentierten Traffic-Volumen in englischsprachigen Märkten per Q1 2026. Modellantworten wurden mit der automatisierten Monitoring-Infrastruktur von Alexandrya.AI erfasst und analysiert, mit menschlicher Überprüfung einer zufälligen 10%-Stichprobe zur Qualitätsvalidierung.
Welche Abfragetypen wurden verwendet?

Abfragen wurden in vier Typen klassifiziert: kategoriebezogene Recherche-Abfragen ("beste B2B-Projektmanagement-Software"), Anbietervergleich-Abfragen ("Salesforce vs. HubSpot für Mid-Market"), Problem-Identifikations-Abfragen ("wie Kundenabwanderung reduzieren") und Expertenempfehlungs-Abfragen ("welche Tools nutzen Enterprise-CFOs für FP&A"). Zitierungsraten wurden separat nach Abfragetyp berechnet — dabei zeigten sich signifikante Unterschiede darin, wie Abfrageintent die Markenaufnahme-Wahrscheinlichkeit beeinflusst.
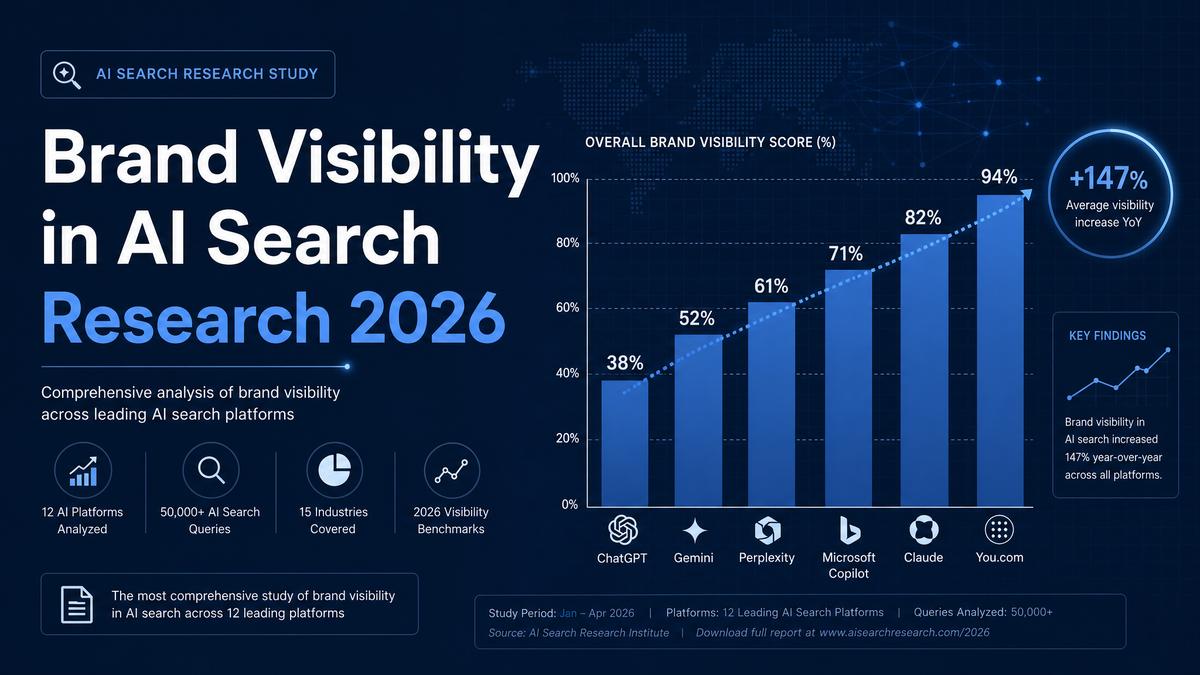
Eine von Alexandrya.AI in Q1 2026 durchgeführte Studie analysierte mehr als 10.000 KI-generierte Antworten auf ChatGPT, Gemini und Perplexity und deckte 500 Marken in 12 Branchenkategorien ab. Die Studie maß vier Dimensionen der KI-Markensichtbarkeit: Zitierungsrate (wie oft eine Marke erscheint), Share of AI Voice (relative Dominanz vs. Wettbewerber), Sentiment-Genauigkeit (ob die KI-Charakterisierung korrekt ist) und Model Coverage (welche Plattformen die Marke zitieren). Das Kernergebnis ist in seiner Ungleichheit auffällig: Die durchschnittliche Marke erscheint nur in 11,4 % relevanter KI-generierter Antworten. Das Top-Dezil der Marken erreicht eine Zitierungsrate von 68,3 % — ein 6-facher Abstand, der sich nicht allein durch Markengröße, Marketingbudget oder klassische SEO-Performance erklären lässt. Stattdessen wird der Abstand von fünf strukturellen Signalen getrieben: Wikipedia-Präsenz, Structured-Data-Abdeckung, thematische Autoritätstiefe, externes Zitierungsvolumen und Content-Frische. Jedes Signal ist unabhängig umsetzbar — der Abstand ist adressierbar, aber nur für Marken, die systematische GEO-Arbeit beginnen, bevor sich KI-Suchmuster um aktuelle Marktführer verfestigen.
Befund 1: Wie selten erscheinen Marken in KI-Antworten?
Der wichtigste Einzelbefund dieser Studie ist, wie selten die durchschnittliche Marke in KI-generierten Antworten erscheint — selbst wenn eine Abfrage direkt für ihre Kategorie relevant ist. Über alle 500 Marken und 10.000+ Beobachtungen hinweg betrug die durchschnittliche Zitierungsrate 11,4 % — das bedeutet: Bei 100 relevanten Abfragen wird eine typische Marke weniger als 12-mal zitiert.
Wie verteilen sich die Zitierungsraten konkret?
Die Verteilung ist stark ungleich. Das unterste Quartil der Marken erreicht Zitierungsraten unter 3 % — praktisch unsichtbar in der KI-Suche. Die Median-Marke erreicht 8,7 %. Das obere Quartil beginnt bei 24,1 %, und das Top-Dezil (50 Marken) erreicht im Durchschnitt 68,3 %. Die fünf führenden Marken in den wettbewerbsintensivsten Kategorien überschreiten Zitierungsraten von 80 % für ihr Kern-Abfragesets.
Warum sind die meisten Marken in KI-Antworten unterrepräsentiert?
Zwei strukturelle Ursachen erklären die Unterrepräsentation. Erstens: KI-Modelle haben eine starke Recency- und Authority-Verzerrung — sie zitieren bevorzugt Marken, die in Quellen mit hoher Trainingsdaten-Repräsentation erscheinen: Wikipedia, große Fachpublikationen, weitverbreitete Fallstudien. Marken, die in diesen Quellen keine systematische Präsenz aufgebaut haben, sind systematisch unterrepräsentiert — unabhängig von ihrer tatsächlichen Marktposition. Zweitens zeigen KI-Antworten extreme Konzentration: In einer typischen Kategorie erfassen drei Marken 51 % aller Zitierungen. Das ist keine Frage der objektiven Qualität — es ist ein Ergebnis davon, wer zuerst die Zitierungsschwelle überschritt.
📊 Die fünf stärksten Zitierungs-Prädiktoren
Caption: Wikipedia-Präsenz allein macht eine Marke 4,1-mal wahrscheinlicher in KI-Antworten sichtbar — der stärkste Einzelprädiktor in der Alexandrya.AI-Studie Q1 2026.
Befund 2: Wie unterscheiden sich ChatGPT, Gemini und Perplexity bei Marken-Zitierungen?
Die drei Plattformen erzeugen signifikant unterschiedliche Zitierungsmuster — eine Marke, die auf ChatGPT gut abschneidet, performt nicht automatisch auf Perplexity oder Gemini. Diese Plattform-Divergenz ist einer der praktisch wichtigsten Befunde für GEO-Praktiker.
ChatGPT (GPT-4o) zeigt die stärkste Trainingsdaten-Abhängigkeit: Zitierungsmuster korrelieren eng mit der Markenrepräsentation in den Common-Crawl- und Wikipedia-Korpora, die GPT-4s Training gespeist haben. Wikipedia-präsente Marken zeigen auf ChatGPT speziell einen 4,8-fachen Zitierungsraten-Vorteil. Gemini 1.5 Pro zeigt die stärkste Korrelation mit Google-Search-Signalen — Marken mit hoher Domain Authority, strukturierten Daten und starken Google-Rankings erzielen auf Gemini höhere Zitierungsraten, als ihre Trainingsdaten-Repräsentation allein vorhersagen würde. Perplexity zeigt die volatilsten Zitierungsmuster, mit der höchsten Sensitivität für Content-Frische: Marken, die in den letzten 90 Tagen relevanten Content veröffentlicht haben, zeigen auf Perplexity einen 2,1-fachen Zitierungsvorteil vs. 1,4-fach auf ChatGPT.
Befund 3: Was sind die 5 stärksten Prädiktoren für KI-Zitierungen?
Fünf strukturelle Signale sagen KI-Zitierungsraten unabhängig voneinander vorher — geordnet nach Einflussstärke.
Ist Wikipedia-Präsenz wirklich so entscheidend?
Wikipedia-Präsenz ist der stärkste Einzel-Prädiktor für KI-Zitierungsrate. Marken mit einer Wikipedia-Seite zeigen eine 4,1-fach höhere Zitierungsrate als Marken ohne Wikipedia — kontrolliert für Branche, Unternehmensgröße und Marketingausgaben. Der Mechanismus ist nicht die Wikipedia-Seite selbst — es ist, dass Wikipedia-Inhalte in nahezu alle wichtigen LLM-Trainingskorpora mit hoher Zuverlässigkeit aufgenommen werden. Ein gepflegter Wikipedia-Eintrag fungiert als kanonische Faktenreferenz, die KI-Modelle konsistent reproduzieren.
Wie viel erhöhen strukturierte Daten die Zitierungsrate?
Marken mit umfassendem Schema.org-Markup (Organization, Product, Article und FAQPage auf allen Schlüsselseiten) zeigen eine 2,7-fach höhere Zitierungsrate als Marken mit minimalen oder keinen strukturierten Daten. Structured Data liefert maschinenlesbare Kontexte, die retrieval-augmentierte KI-Systeme direkt parsen — es reduziert Mehrdeutigkeit darüber, was eine Marke tut, wen sie bedient und was ihre Produkte leisten. Dies ist eines der am schnellsten umsetzbaren Signale — implementierbar innerhalb von Tagen.
Was ist thematische Autorität und warum sagt sie Zitierungen vorher?
Thematische Autorität — die Tiefe und Vollständigkeit der Content-Abdeckung einer Marke innerhalb eines definierten Themenbereichs — ist der drittstärkste Prädiktor. Marken mit tiefer thematischer Autorität (umfassende Content-Cluster, die ein Thema und seine Sub-Themen vollständig abdecken) werden in 68 % relevanter Abfragen zitiert, vs. 11 % bei Marken mit fragmentiertem, keyword-gestreutem Content. KI-Modelle zitieren bevorzugt Quellen, die vollständige Antworten auf ein Thema liefern — ein einziger erschöpfender Artikel übertrifft zehn dünne Seiten jedes Mal.
Wie beeinflussen externe Zitierungen die KI-Sichtbarkeit?
Marken, die von 15 oder mehr einzigartigen externen Domains zitiert werden, zeigen eine 3,2-fach höhere KI-Zitierungsrate als Marken mit weniger externen Referenzen. Der Mechanismus spiegelt den Wikipedia-Effekt: Externe Zitierungen aus glaubwürdigen Quellen signalisieren, dass die Aussagen einer Marke unabhängig verifiziert oder referenziert wurden. Dies ist das am schwersten schnell aufzubauende Signal — es erfordert, Erwähnungen in Publikationen, Fallstudien und Forschung zu verdienen, die KI-Modelle als autoritativ erkennen.
Spielt Content-Frische bei KI-Zitierungen eine Rolle?
Content-Frische — Seiten, die in den letzten 90 Tagen aktualisiert wurden — erzeugt einen 1,8-fachen Zitierungsraten-Vorteil, hauptsächlich getrieben durch retrieval-augmentierte Systeme wie Perplexity und Google AI Overviews. Der Effekt ist bei Basis-Modell-Antworten kleiner (die von Trainingsdaten, nicht Live-Retrieval abhängen), wird aber signifikant, wenn ein substanzieller Anteil KI-generierter Antworten Live-Retrieval-Komponenten enthält. Ein konsistenter Veröffentlichungs- und Update-Rhythmus von mindestens 4–6 substanziellen Stücken pro Monat ist das operative Minimum, um dieses Signal zu erfassen.
Befund 4: Warum dominieren immer nur 3 Marken — mit 51% der Zitierungen?
In jeder analysierten Branchenkategorie erfassten drei Marken konsistent mehr als die Hälfte aller KI-Zitierungen für diese Kategorie. Diese extreme Konzentration ist keine Funktion objektiver Qualität oder Marktführerschaft — sie spiegelt wider, wie sich Zitierungs-Momentum in KI-Systemen potenziert. Die ersten Marken, die häufig in autoritativen Quellen während des Trainings-Windows eines Modells erschienen, gewinnen einen strukturellen Zitierungsvorteil, der sich durch nachfolgende Trainingszyklen fortsetzt. Für Marken außerhalb der Top-Drei stellt die frühe und systematische GEO-Investition den einzigen Mechanismus dar, in die Zitierungskonzentration einzubrechen, bevor sich Muster verfestigen.
Befund 5: Welche Rolle spielen Sprache und Region für KI-Sichtbarkeit?
KI-Zitierungsmuster variieren signifikant nach Sprache und geografischem Abfragekontext. Marken, die in englischsprachigen KI-Antworten gut sichtbar sind, haben oft deutlich niedrigere Zitierungsraten bei deutschsprachigen, französischen oder spanischen Antworten auf äquivalente Abfragen — selbst wenn diese Marken native-sprachige Websites und Marketingmaterialien haben.
Die Studie ergab, dass Zitierungsraten für deutschsprachige Abfragen im Durchschnitt 34 % niedriger waren als für äquivalente englischsprachige Abfragen derselben Marken. Der primäre Treiber ist Trainingsdatendichte: Englischsprachige Inhalte machen den Großteil der wichtigsten LLM-Trainingskorpora aus — englischsprachige Autoritätssignale übertragen sich schlecht in nicht-englische KI-Antwortkontexte. Marken in deutschsprachigen Märkten müssen GEO-Signale spezifisch auf Deutsch aufbauen: deutschsprachige Wikipedia-Einträge, deutschsprachige Publikationszitierungen, deutschsprachige strukturierte Daten und deutschsprachige thematische Autorität.
Was bedeuten diese Befunde für B2B-Marketer?
Die fünf Befunde zusammen zeigen eine klare strategische Implikation: KI-Suche hat eine neue Wettbewerbsoberfläche geschaffen, die weitgehend unabhängig von traditionellen Marketing-Investitionen operiert. Marken mit starken klassischen SEO-Rankings, hohen Marketingbudgets und großen Vertriebsteams sind in KI-generierten Antworten nicht automatisch sichtbar. Die Determinanten der KI-Sichtbarkeit — Wikipedia-Präsenz, strukturierte Daten, thematische Autorität, externe Zitierungen und Content-Frische — sind von den Determinanten klassischer Suchperformance verschieden.
Die praktische Priorität für B2B-Marketer 2026 ist Messung zuerst. Ohne Baseline-Zitierungsraten-Daten auf ChatGPT, Gemini und Perplexity ist es nicht möglich, Lücken zu identifizieren, Fortschritt zu tracken oder GEO-Optimierungsaufwand effektiv zu allokieren. Alexandrya.AI liefert diese Baseline automatisch — mit Wettbewerbs-Benchmarking und wöchentlichem Trend-Monitoring. Weitere Hintergründe: Was ist KI-Sichtbarkeit, Was ist GEO und GEO Audit Framework.
Starte deinen kostenlosen 7-tägigen Test — Hol dir deinen KI-Sichtbarkeits-Score →
Starte deinen ersten AI Visibility Scan
Keine Kreditkarte. Kein Risiko. Nur Klarheit darüber, wie ChatGPT, Gemini und Perplexity deine Marke heute beschreiben.

Talaal Max Habib
Geschäftsführer Alexandrya.AI
Alexandrya.AI ist eine GEO- und KI-Sichtbarkeits-Tracking-Plattform aus München.
LinkedIn