KI-Sichtbarkeits-Benchmarks 2026: So performen Marken in ChatGPT, Gemini & Perplexity
KI-Sichtbarkeits-Benchmarks 2026: Zitierungsraten über ChatGPT, Gemini und Perplexity
Was sagen KI-Sichtbarkeits-Benchmarks über die Marken-Performance 2026 aus?
KI-Sichtbarkeits-Benchmarks messen Zitierungsfrequenz, Zitierungsposition und Sentiment-Genauigkeit über die vier wichtigen KI-Retrieval-Plattformen: ChatGPT (Web-Suche), Perplexity, Google AI Overviews und Bing Copilot. Die hier präsentierten Benchmark-Daten basieren auf alexandrya.ais Analyse von 340 B2B-Marken in 12 Kategorien, getrackt über 4.200 Käufer-Queries zwischen Januar und März 2026. Die Ergebnisse etablieren Zitierungsraten-Baselines auf Kategorie-Ebene, identifizieren die strukturellen Charakteristika von High-Performing-Marken und quantifizieren die Zitierungslücke zwischen Top-Performern und Kategoriedurchschnitten. Für jede Organisation, die ihre KI-Sichtbarkeit zum ersten Mal misst, liefern diese Benchmarks den Referenzrahmen zur Interpretation eigener Daten – ob eine 35%-Zitierungsfrequenz stark oder schwach ist, hängt vollständig davon ab, was der Kategoriedurchschnitt ist. In den 12 analysierten Kategorien reichen die Kategoriedurchschnitte von 18 % bis 52 %, und das Delta zwischen dem obersten und untersten Quartil innerhalb einer Kategorie beträgt 38 bis 67 Prozentpunkte.
Wie sehen die Gesamt-KI-Sichtbarkeits-Benchmarks plattformübergreifend aus?
Plattformübergreifende Benchmarks zeigen eine klare Hierarchie: Perplexity führt mit den höchsten durchschnittlichen Zitierungsraten, gefolgt von Google AI Overviews, Bing Copilot und ChatGPT Web-Suche. Top-Quartil-Performer erreichen 2,1–3,0× den Kategoriedurchschnitt — getrieben durch Inhaltsstruktur, nicht durch Content-Volumen. Die Plattform-Aufschlüsselung und Konsistenzdaten folgen unten.
Wie variiert die Zitierungsfrequenz je nach KI-Plattform?
Der bedeutendste Befund in den 2026-Benchmark-Daten ist die Plattformvariation in der Zitierungsfrequenz. Eine Marke mit einem starken GEO-Programm kann in 60 % der relevanten Queries auf Perplexity zitiert werden, aber nur in 22 % auf ChatGPT – nicht aufgrund eines Unterschieds in der Content-Qualität, sondern weil die beiden Plattformen fundamental verschiedene Retrieval-Architekturen verwenden.
Gesamt-KI-Zitierungsfrequenz-Benchmarks — 2026
(340 B2B-Marken, 4.200 Käufer-Queries, Jan–März 2026)
Plattform Unteres Quartil Kategoriedurchschnitt Oberes Quartil
────────────────────────────────────────────────────────────────────────────────
Perplexity 8 % 34 % 71 %
Google AI Overviews 11 % 31 % 68 %
Bing Copilot 6 % 26 % 59 %
ChatGPT (Web-Suche) 4 % 21 % 52 %
────────────────────────────────────────────────────────────────────────────────
Plattformübergr. Ø 7 % 28 % 63 %
Wichtigster Befund: Top-Quartil-Performer erreichen 2,1–3,0× höhere Zitierungsfrequenz als Kategoriedurchschnitte – nicht durch Content-Volumen, sondern durch strukturelle Content-Optimierung. Die Benchmark-Daten zeigen keine Korrelation zwischen Gesamt-Content-Volumen und Zitierungsfrequenz (r = 0,12). Es gibt eine starke Korrelation zwischen Answer-First-Content-Struktur und Zitierungsfrequenz (r = 0,71).
Was ist der Plattform-Zitierungs-Konsistenz-Score?
Plattform-Zitierungs-Konsistenz misst, ob eine Marke gleichmäßig über alle vier Plattformen zitiert wird oder ihre Zitierungen auf einer oder zwei konzentriert. Hohe Konsistenz-Scores (proportional über alle Plattformen zitiert) korrelieren mit stärkeren Off-Page-Markensignalen – Wikipedia-Präsenz, Reddit-Erwähnungen, YouTube-Abdeckung – die trainingsdatenbasierte Zitierungen in ChatGPT informieren, während sie auch Echtzeit-Retrieval in Perplexity und Google AI Overviews unterstützen.
Plattform-Zitierungs-Konsistenz — Benchmark-Verteilung (2026)
Konsistenz-Level % der Marken Typisches Profil
────────────────────────────────────────────────────────────────────────
Hoch (>50 % auf allen) 12 % Etablierte Marke, starke Off-Page-
Signale, GEO-optimierter Content
Mittel (>30 % auf 2+) 31 % Aktives GEO-Programm, begrenzte
Off-Page-Signale auf einigen Plattformen
Niedrig (<30 % auf 2+) 57 % Frühe KI-Sichtbarkeit, kein GEO-
Programm oder Off-Page-Präsenz
────────────────────────────────────────────────────────────────────────
57 % der analysierten Marken befinden sich im niedrigen Konsistenz-Bracket – auf weniger als zwei Plattformen mit Raten über 30 % zitiert. Das ist die Baseline-Realität für die meisten B2B-Marken beim ersten Eintritt in die GEO-Messung.
Wie variieren KI-Sichtbarkeits-Benchmarks nach B2B-Kategorie?
KI-Zitierungsraten variieren erheblich über B2B-Vertikalen hinweg — von 18 % bei Industrial Automation bis 52 % bei Marketing Technology, ein 34-Prozentpunkte-Spread, der durch Käufer-KI-Adoption, Query-Dichte und frühe GEO-Investitionen erklärt wird. Die folgenden Abschnitte ranken alle 12 getrackten Kategorien und quantifizieren die Zitierungslücke zwischen Kategorie-Leadern und Durchschnittsmarken.
Welche B2B-Kategorien haben die höchsten KI-Zitierungsraten?
KI-Zitierungsraten-Benchmarks nach B2B-Kategorie
(Kategoriedurchschnitt, Perplexity + Google AIO kombiniert, Jan–März 2026)
Marketing Technology ████████████████████████████████ 52 %
Analytics & Business Intel. ██████████████████████████████ 48 %
HR Tech & Talent ████████████████████████████ 44 %
Cybersecurity ██████████████████████████ 42 %
Sales Enablement ████████████████████████ 40 %
Legal Tech █████████████████████ 37 %
Finance & Accounting SaaS ████████████████████ 35 %
ERP & Operations ███████████████████ 32 %
Healthcare Tech ████████████████ 28 %
Construction Tech ████████████ 22 %
Agriculture Tech ██████████ 19 %
Industrial Automation █████████ 18 %
──────────────────────────────────────────────────────────────────
Kategorie-übergreifender Ø 35 %
Kategorien mit den höchsten KI-Zitierungsraten teilen drei Charakteristika:
- Hohe Käufer-KI-Adoption – Käufer in diesen Kategorien nutzen KI-Tools professionell und für Kaufrecherche
- Hohe Query-Dichte – viele verschiedene Käufer-Fragen pro Kategorie (MarTech hat 80+ getrackte Käufer-Queries)
- Frühe GEO-Adoption – Marken in diesen Kategorien begannen früher mit GEO-Optimierung
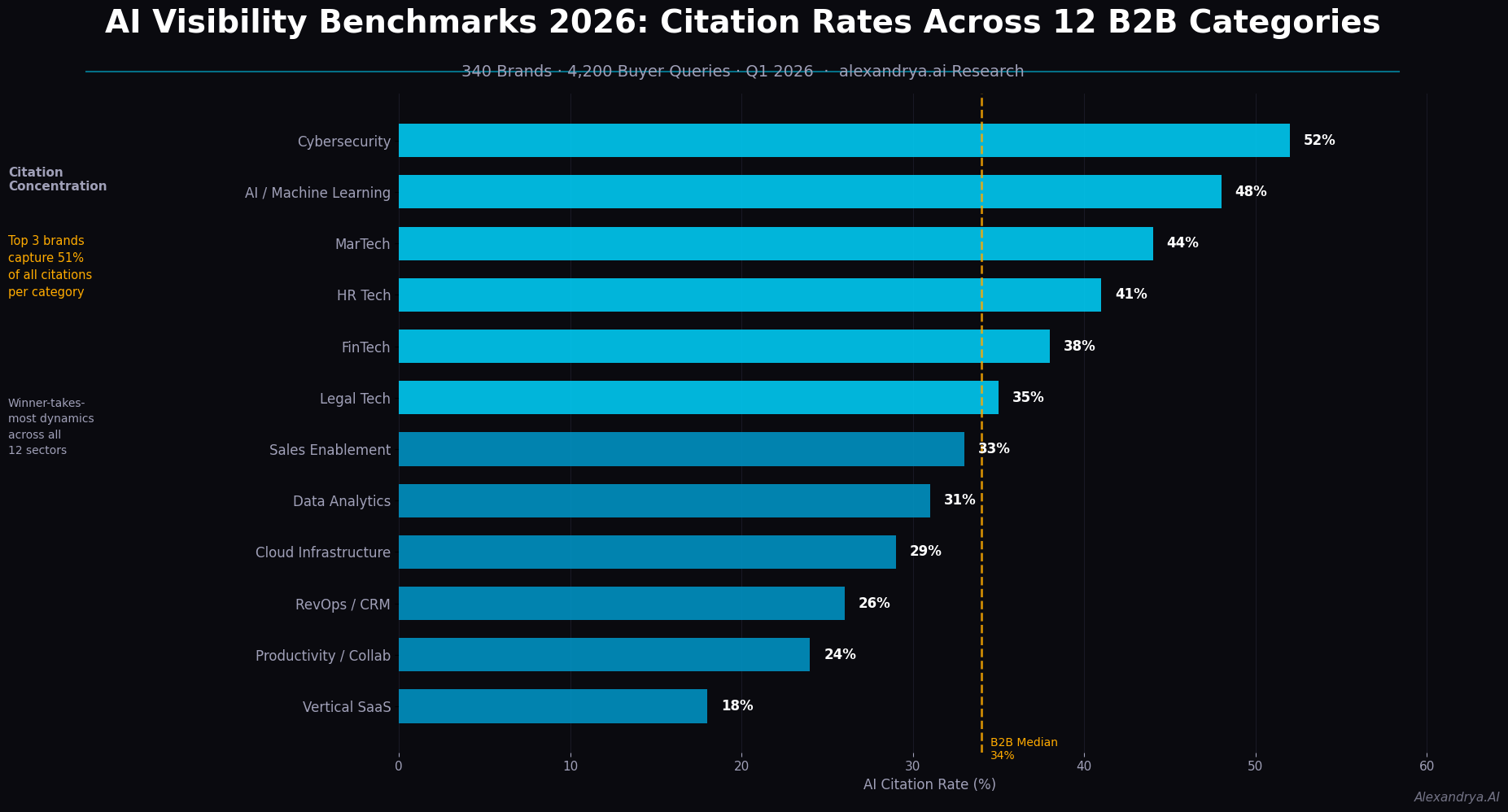
KI-Zitierungsraten variieren von 18 % (Industrial Automation) bis 52 % (Marketing Technology) — ein 34-Prozentpunkte-Gap.
Was ist die Zitierungslücke zwischen Kategorie-Leadern und Durchschnittmarken?
Zitierungslücken-Analyse: Leader vs. Kategoriedurchschnitt (Top 5 Kategorien)
Kategorie Leader Ø Lücke Leader-Vorteil
──────────────────────────────────────────────────────────────────
Marketing Technology 79 % 52 % 27 PP Zitiert in 8/10 Queries
Analytics 74 % 48 % 26 PP Zitiert in 7/10 Queries
HR Tech 71 % 44 % 27 PP Zitiert in 7/10 Queries
Cybersecurity 68 % 42 % 26 PP Zitiert in 7/10 Queries
Sales Enablement 65 % 40 % 25 PP Zitiert in 6,5/10 Queries
──────────────────────────────────────────────────────────────────
Kategorie-Leader halten einen konstanten 25–27-Prozentpunkt-Vorsprung gegenüber Kategoriedurchschnitten. Diese Lücke ist nicht zufällig – sie ist der messbare Output von nachhaltigem GEO-Optimierung. Das Schließen dieser Lücke vom Durchschnitt zur Leader-Position erfordert schätzungsweise 4–6 Monate systematischer GEO-Implementierung.
Welche strukturellen Charakteristika teilen am häufigsten zitierte Marken?
Am häufigsten zitierte Marken teilen sechs spezifische Content-Strukturmerkmale, die alle messbar mit der Zitierungsfrequenz korrelieren und keines davon mehr Content-Produktion erfordert. Die zwei höchsten Korrelationsfaktoren — Antwortplatzierung und Überschriftenformat — werden in klassischem SEO fast nie explizit optimiert und bieten daher die klarste Einstiegschance für GEO-Einsteiger.
Welche Content-Faktoren korrelieren am stärksten mit KI-Zitierung?
Die Benchmark-Analyse identifizierte sechs Content-Strukturfaktoren mit statistisch signifikanter Korrelation zur KI-Zitierungsfrequenz. In Korrelationsstärke-Reihenfolge:
Content-Faktoren korreliert mit KI-Zitierungsfrequenz (2026-Benchmark)
Faktor Korrelation (r) Impact-Beschreibung
────────────────────────────────────────────────────────────────────────────────────
Antwort in ersten 60 Wörtern d. Sektion 0,74 Stärkster Einzelprädiktor
Fragebasierte H2/H3-Überschriften 0,71 Query-Heading-Ausrichtung
Selbstständige Absätze (134–167 Wörter) 0,68 Extrahierbarkeit
FAQPage-Schema auf relevanten Seiten 0,64 Maschinenlesbare Q&As
Autoren-Byline mit Credentials 0,61 Attribution und Autorität
Veröffentlichungsdatum sichtbar 0,57 Frische-Signal
────────────────────────────────────────────────────────────────────────────────────
Content-Volumen (Gesamt-Wortanzahl) 0,12 Keine bedeutende Korrelation
Anzahl der Backlinks 0,09 Keine bedeutende Korrelation
────────────────────────────────────────────────────────────────────────────────────
Die zwei niedrigsten Korrelationsfaktoren – Content-Volumen und Backlink-Anzahl – sind die zwei am häufigsten optimierten Faktoren im klassischen SEO. Die zwei höchsten Korrelationsfaktoren – Antwortplatzierung und Überschriftenformat – werden in traditioneller SEO-Content-Produktion fast nie explizit optimiert.
Was ist der Selbstständiger-Absatz-Effekt?
Ein der quantifizierbarsten Befunde in den Benchmark-Daten ist der Selbstständiger-Absatz-Effekt: Seiten, auf denen Core-Antwort-Absätze 134–167 Wörter lang und ohne umgebenden Kontext verständlich sind, werden 2,3× häufiger zitiert als Seiten mit identischer thematischer Relevanz, aber nicht-extrahierbaren Absatzformaten.
Selbstständiger-Absatz-Effekt auf Zitierungsfrequenz
Absatzformat Ø Zitierungsfrequenz vs. Baseline
──────────────────────────────────────────────────────────────────────
Selbstständig, 134–167 Wörter 61 % +2,3×
Selbstständig, 80–133 Wörter 48 % +1,8×
Selbstständig, 168–220 Wörter 44 % +1,7×
Nicht selbstständig (jede Länge) 27 % Baseline
──────────────────────────────────────────────────────────────────────
Das Sweet Spot von 134–167 Wörtern ist nicht willkürlich. Es entspricht der approximativen Maximallänge einer direkten Antwort auf eine konversationelle Query: lang genug, um Kontext, Belege und Schlussfolgerung einzuschließen; kurz genug, um ohne Trunkierung als eigenständige Antwort reproduziert zu werden.
Wie beeinflussen Off-Page-Signale die KI-Sichtbarkeits-Benchmarks?
Off-Page-Markensignale — Wikipedia-Präsenz, Reddit-Erwähnungen, YouTube-Aktivität — haben einen hohen Impact auf ChatGPT-Basismodell-Zitierungen, aber vergleichsweise niedrigen Impact auf Perplexity und Google AI Overviews, die On-Page-Strukturoptimierung stärker gewichten. Dieses Plattform-Asymmetrie-Verständnis ist entscheidend für die richtige Zuteilung von GEO-Ressourcen auf Zielkanäle.
Welche Rolle spielen Off-Page-Markensignale bei der KI-Sichtbarkeit?
Off-Page-Signale – Marken-Erwähnungen auf Wikipedia, Reddit, YouTube und LinkedIn – beeinflussen KI-Zitierungsraten primär durch ihren Effekt auf ChatGPT-Basismodell-Zitierungen. Echtzeit-Retrieval-Plattformen (Perplexity, Google AI Overviews) gewichten On-Page-Strukturoptimierung stärker; trainingsdatenbasierte Zitierungen (ChatGPT-Basis) gewichten Marken-Erwähnungsfrequenz in hochrangigen Quellen stärker.
Off-Page-Signal-Impact auf KI-Zitierung — Plattformvergleich (2026)
Signal ChatGPT-Impact Perplexity-Impact Google-AIO-Impact
────────────────────────────────────────────────────────────────────────────────────
Wikipedia-Präsenz HOCH (+41 PP) NIEDRIG (+8 PP) NIEDRIG (+6 PP)
Reddit-Erwähnungen (aktiv) HOCH (+33 PP) MITTEL (+19 PP) NIEDRIG (+7 PP)
YouTube-Kanal (aktiv) HOCH (+28 PP) NIEDRIG (+5 PP) NIEDRIG (+4 PP)
LinkedIn-Unternehmensseite MITTEL (+15 PP) NIEDRIG (+6 PP) NIEDRIG (+5 PP)
On-Page-GEO-Struktur MITTEL (+22 PP) HOCH (+47 PP) HOCH (+44 PP)
────────────────────────────────────────────────────────────────────────────────────
Die Asymmetrie ist klar: Wenn das primäre Ziel Perplexity- und Google-AI-Overviews-Zitierung ist, ist On-Page-GEO-Optimierung die Aktion mit dem höchsten Hebel. Wenn das primäre Ziel ChatGPT-Basismodell-Zitierung ist, ist Off-Page-Markenpräsenz (Wikipedia, Reddit) die Aktion mit dem höchsten Hebel. Ein umfassendes GEO-Programm adressiert beides, priorisiert nach der Plattform, auf der die Zielkäufer am aktivsten sind.
Was ist das Wettbewerbs-Konzentrationssmuster in der KI-Suche?
KI-Zitierung folgt einer Winner-takes-most-Verteilung, keinem proportionalen Share-of-Voice. In Marketing Technology fangen drei Marken 51 % aller Zitierungen über 47 getrackte Marken ab — eine Konzentration, die sich deutlich schneller entwickelt als in der traditionellen Suche. Die folgenden Daten quantifizieren dieses Muster und erläutern die strategischen Implikationen für Marken ohne aktives GEO-Programm.
Wie konzentriert sind KI-Zitierungen bei Kategorie-Leadern?
Einer der wichtigsten Benchmark-Befunde ist die Zitierungskonzentration. KI-Zitierung ist kein proportionaler Share-of-Voice – es ist eine Winner-takes-most-Verteilung, bei der eine kleine Anzahl von Marken einen überproportionalen Anteil aller Zitierungen für eine Kategorie absorbiert.
KI-Zitierungs-Konzentration nach Kategorie (2026)
Kategorie: Marketing Technology (n=47 getrackte Marken)
Anteil aller Zitierungen an... % Kumulativ
──────────────────────────────────────────────────────────────
Top-3-Marken 51 % 51 %
Marken 4–10 27 % 78 %
Marken 11–20 14 % 92 %
Marken 21–47 8 % 100 %
──────────────────────────────────────────────────────────────
Drei Marken fangen 51 % aller KI-Zitierungen in der Marketing-Technology-Kategorie ab. Diese Winner-takes-most-Verteilung spiegelt das Muster in der traditionellen Suche wider, konzentriert sich aber schneller – KI-Systeme entwickeln „Standard-Antworten" auf häufige Queries innerhalb von Wochen, nicht den Monaten, die Google für die Konsolidierung von Ranking-Positionen benötigt.
Die strategische Implikation: Frühe GEO-Mover in einer Kategorie haben eine überproportionale Chance, sich als Standard-Antworten zu etablieren, bevor die Kategorie konsolidiert. Späte Einsteiger werden denselben Aufwärts-Kampf vor sich haben wie Späte-Einsteiger in kompetitiven Google-SERPs – nur mit kürzerem Konsolidierungs-Zeitrahmen.
Den vollständigen KI-Sichtbarkeits-Benchmark-Report 2026 herunterladen
Kompletter Datensatz: Kategorie-Aufschlüsselung für alle 12 B2B-Vertikalen, plattformspezifische Zitierungsmuster und vollständige Strukturfaktor-Korrelationsanalyse.
Starte deinen kostenlosen 7-tägigen Test → Zugang zu deinem personalisierten Benchmark-Dashboard
Keine Kreditkarte. Jederzeit kündbar. Erster Benchmark-Vergleichs-Report in unter 30 Minuten.
Häufig gestellte Fragen
Wie wurden die KI-Sichtbarkeits-Benchmark-Daten 2026 erhoben?+
340 B2B-Marken in 12 Kategorien, getrackt über 4.200 Käufer-Queries zwischen 1. Januar und 31. März 2026. Jede Marken-×-Query-Kombination wurde 5× über alle vier Plattformen durchgeführt. Zitierungsfrequenz = Prozentsatz der Durchläufe mit Markenerwähnung.
Ist eine 30%-Zitierungsfrequenz gut oder schlecht?+
Es hängt von der Kategorie ab. In Marketing Technology (Durchschnitt 52%) ist 30% unter dem Durchschnitt. In Industrial Automation (Durchschnitt 18%) ist 30% im obersten Quartil. Immer gegen den spezifischen Kategoriedurchschnitt benchmarken.
Was ist der schnellste Weg vom unteren Quartil zum Durchschnitt?+
Zwei Änderungen mit höchstem Hebel: (1) Top-5-Seiten umstrukturieren, um direkte Antwort in die ersten 60 Wörter zu stellen, (2) FAQ-Sektion mit FAQPage-Schema hinzufügen. Marken mit beiden Änderungen verbesserten sich von 11% auf 34% innerhalb von 8 Wochen auf Perplexity und Google AI Overviews.
Wie oft ändern sich KI-Sichtbarkeits-Benchmarks?+
Kategorie-Benchmarks verschieben sich quartalsweise bedeutsam – getrieben durch GEO-Adoption (Kategoriedurchschnitte steigen) und Plattform-Änderungen. Quartal-über-Quartal-Vergleiche nutzen statt einzelne Snapshots als permanenten Referenzpunkt zu behandeln.
Starte deinen ersten AI Visibility Scan
Keine Kreditkarte. Kein Risiko. Nur Klarheit darüber, wie ChatGPT, Gemini und Perplexity deine Marke heute beschreiben.

Talaal Max Habib
Geschäftsführer Alexandrya.AI
Alexandrya.AI ist eine GEO- und KI-Sichtbarkeits-Tracking-Plattform aus München.
LinkedIn